

If you’re looking to boost operational efficiency in your business, you can use supervised and unsupervised machine learning techniques. Two such approaches are classification and clustering, both of which help you analyse and group your data. Classification allows you to categorise labelled data, whereas clustering detects patterns within an unlabelled set. That said, in comparing the two, classification vs clustering, when should you use each in your business?
What is classification?
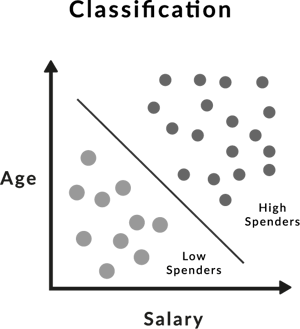
As noted above, classification allows you to categorise labelled data. More than that, you can use a classification algorithm to predict a discrete value. Also known as a categorical value, a discrete value is a clear classification. A typical example could be brand, colour or flavour. This is possible because this technique identifies the input data as a part of a specific category or group.
Classification is, therefore, a supervised machine learning technique that you can use to categorise your data according to various features. It’s a supervised method because you will make use of a labelled dataset where the output of the algorithm is known. This works by setting rules to linearly separate the data points using a decision boundary.
You would also use a classification algorithm to assign each data point to a specific class. For example, you could use it to label an apple as a fruit or vegetable on your database or classify products by department, category, subcategory or even segment.
Classification is a two-phase process. The first stage refers to the training step, while the second stage is where you’d classify the data. You will need to train the algorithm on a correctly classified dataset. This ensures that the points in your dataset are classified correctly once you run the algorithm. Once you have classified your data, you can check the accuracy of the algorithm by evaluating precision and sensitivity to identify the correct output.
What is clustering?
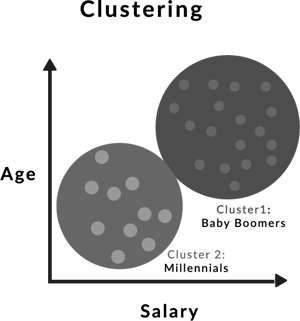
While classification is a supervised machine learning technique, clustering or cluster analysis is the opposite. It’s an unsupervised machine learning technique that you can use to detect similarities within an unlabelled dataset. Clustering algorithms use distance measures to group or separate data points. This produces homogeneous groups that differ from one another.
Clustering is also different from classification in that it follows a single-phase approach, where you provide the input data to the system without knowing the output or groupings. This technique also allows you to set the clustering parameters which should align with your business strategy and goals. For example, you can cluster a dataset according to brand, subcategory, sales and so on.
You can use clustering to find similarities and patterns within your customer base and product categories. This is possible because clustering within retail will help you to group your data and transform it into an understandable format from which you can generate insights. To achieve results that will make a difference in your business, a clustering algorithm tailored to the market environment is paramount.
Classification vs Clustering: what are the key differences?
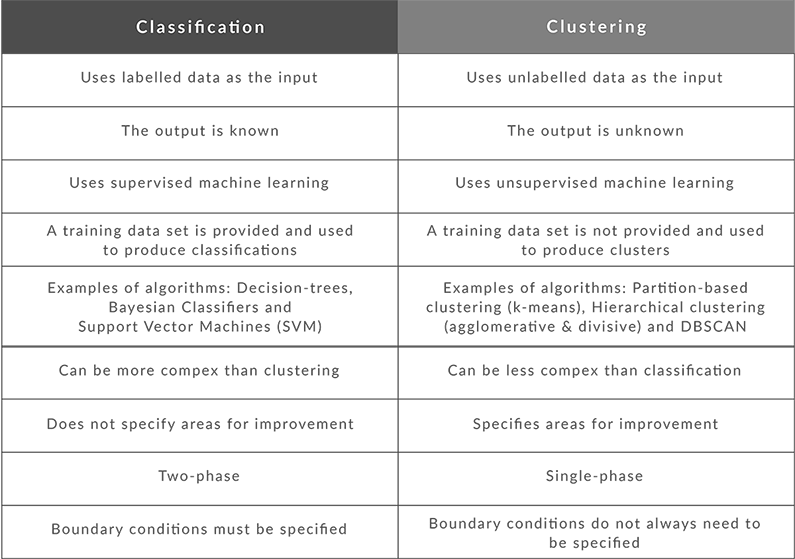
Although you can use these approaches to categorise data points into one or more groups based on specific variables, there are some distinct differences between classification and clustering.

How you can use classification or clustering in your business
Classification and clustering have various applications in the industry. Some options are unpacked below.
Applying classification to your business
1. K-Nearest Neighbour
K-Nearest Neighbour (KNN) is a simple and effective algorithm that you can use in conjunction with product search bars and recommendation systems on your website. This algorithm uses predictions by searching the data or training set for the closest match to the original data point or term searched online in this case.
When a customer searches for a specific product on your website, the algorithm will show them similar items that may be related to the original search term. Other products that may be frequently purchased with the product are also recommended to the shopper at this point.
2. Decision Trees
Decision Trees are a classification method used primarily for predictive modelling. You might have come across it with regards to classifying your products.
This method creates a binary tree with input variables (nodes) and output variables (predictions). Predictions are made by following the decision all the way to the leaf node (the output). Decision trees can help you to map out the consumer decision-making process for a particular product category in the form of a consumer decision tree.
You can also use this method to help consumers choose a product that will meet their needs. You can implement this in the form of a quiz/questionnaire where each choice your shopper makes will lead them to a final recommendation of a product.
3. Consumer behaviour classification
You can also use classification to label your customer base according to certain factors.
For example, you could classify shoppers according to brand loyalty for a particular brand. You can use this information to target non-brand loyal customers with marketing to encourage brand switching. You can also use classification to detect fraudulent transactions for an online store using historical sales data.
Applying clustering to your business
On the other hand, you can also use clustering to help you reach your business goals.
1. Segment and profile customer base
You can make use of cluster analysis to segment and profile your customer base. You can group shoppers according to variables that are in line with your business goals, such as demographics, behavioural characteristics or performance data.
It can be assumed that shoppers who fall within the same cluster exhibit the same consumer behaviour, and you can thus target them in the same manner. This will allow you to understand your target market and offer the right products at the right time, place and price.
2. Assortment planning and space apportionment
You can also use clustering within the assortment and space planning functions. By understanding each cluster, you can develop specialised customer-centric product ranges. This information feeds into the apportionment of floor and shelf space, due to the needs of the consumers in the cluster, and the subsequent assortment plan that you may have previously developed.
If you want to know how to use classification and clustering techniques in your business, you can read more about supervised and unsupervised machine learning.
Conclusion
Classification and clustering are two effective machine learning techniques that you can use to enhance your business processes. Although these processes are similar, you can use them differently to understand your shoppers and improve the customer shopping experience at your store. By analysing, profiling and targeting your consumers using machine learning, you will ultimately create a loyal customer base and an optimised return on investment.
Looking for assistance when choosing between supervised and unsupervised machine learning? Let DotActiv help. Find out more about our cluster optimization service or book a complimentary meeting with a DotActiv expert.
